Since Spark 2.3 was officially released 2/28/18, I wanted to check the performance of the new Vectorized Pandas UDFs using Apache Arrow.
Following up to my Scaling Python for Data Science using Spark post where I mentioned Spark 2.3 introducing Vectorized UDFs, I’m using the same Data (from NYC yellow cabs) with this code:
from pyspark.sql import functions as F
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.types import *
import pandas as pd
df = spark.read\
.option("header", "true")\
.option("inferSchema", "true")\
.csv("yellow_tripdata_2017-06.csv")
def timestamp_to_epoch(t):
return t.dt.strftime("%s").apply(str) # <-- pandas.Series calls
f_timestamp_copy = pandas_udf(timestamp_to_epoch, returnType=StringType())
df = df.withColumn("timestamp_copy", f_timestamp_copy(F.col("tpep_pickup_datetime")))
df.select('timestamp_copy').distinct().count()
# s = pd.Series({'ds': pd.Timestamp('2018-03-03 04:31:19')})
# timestamp_to_epoch(s)
## ds 1520080279
## dtype: object
Pandas Scalar (the default; as opposed to grouped map) UDFs operate on pandas.Series objects for both input and output, hence the .dt call chain as opposed to directly calling strftime on a python datetime object. The entire functionality is dependent on using PyArrow (>= 0.8.0).

Expect errors to crop up as this functionality is new. I have seen a fair share of memory leaks and casting errors causing my jobs to fail during testing.
Running the job above shows some new items in the Spark UI (DAG) and explain plan:
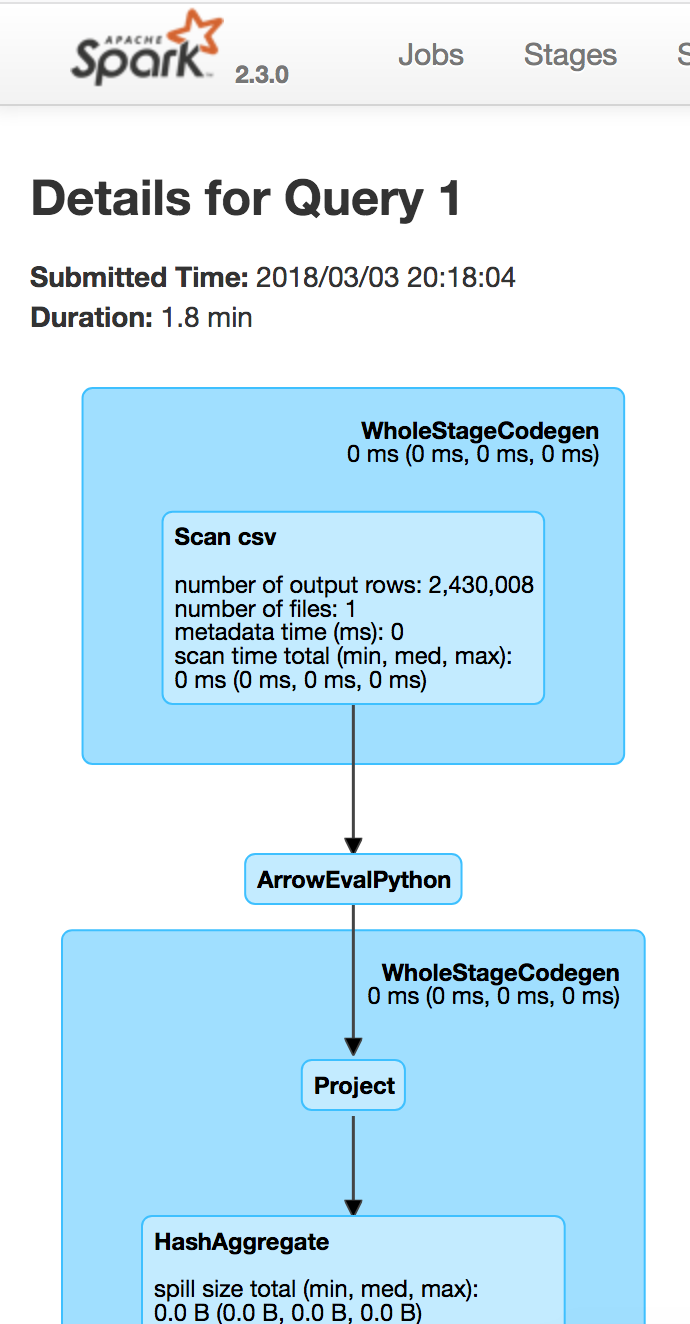

Note the addition of ArrowEvalPython
What’s the performance like?!
To jog your memory, PySpark SQL took 17 seconds to count the distinct epoch timestamps, and regular Python UDFs took over 10 minutes (610 seconds).
Much to my dismay, the performance of my contrived test was in line with Python UDFs, not Spark SQL with a runtime of 9-10 minutes.
I’ll update this post [hopefully] as I get more information.
Thank you so much Jossie!