![]()
Apache Spark and Parquet (SParquet) are a match made in scalable data analytics and delivery heaven. Spark brings a wide ranging, powerful computing platform to the equation while Parquet offers a data format that is purpose-built for high-speed big data analytics. If this sounds like fluffy marketing talk, resist the temptation to close this tab, because what follows are substantial insights I’ve personally procured and am sharing here to help others get the most out of Parquet and Spark.
What is Parquet?
Parquet is a binary compressed columnar file format available to any project in the Hadoop ecosystem (and others outside it even). It’s a mouthful, but let’s break it down.
Binary means parquet files cannot be opened by typical text editors natively (sublime text*, vim, etc).
* My former colleague James Yu wrote a Sublime Text plugin you can find here to view parquet files.
Columnar means the data is stored as columns instead of rows as most traditional databases (MySQL, PostgreSQL, etc) and file formats (CSV, JSON, etc). This is going to be very important.
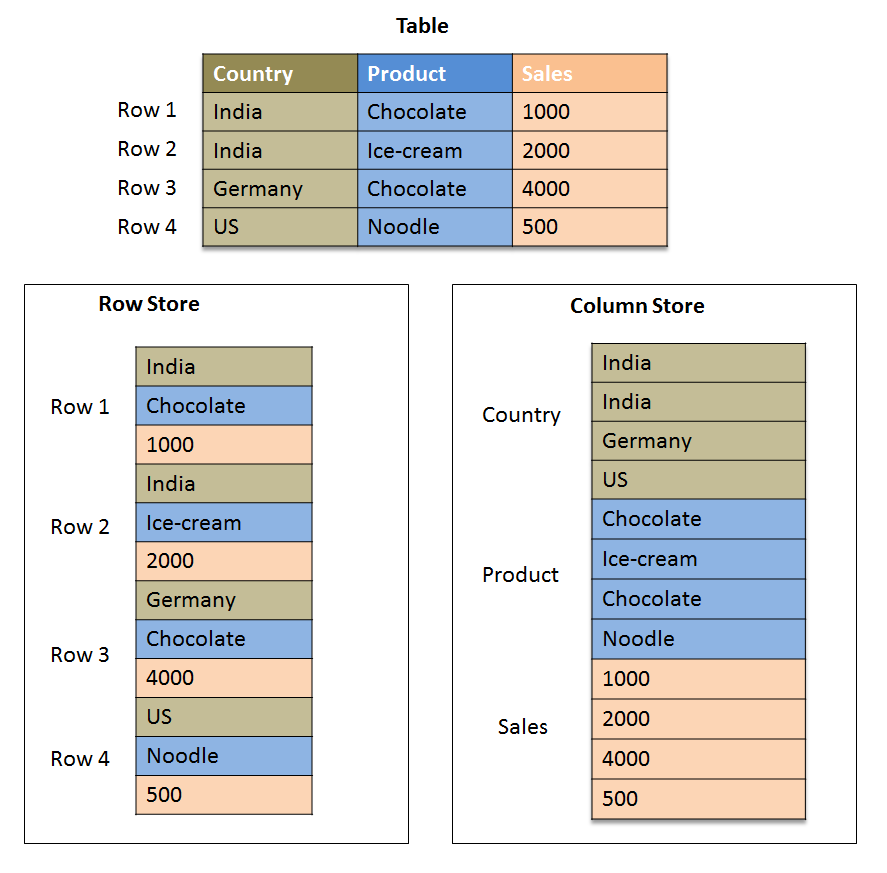
Compressed means the file footprint on disk (HDFS, S3, or local filesystem) is smaller than a typical raw uncompressed file. Parquet handles compression differently than traditional compression of a CSV file for example, but in a similar vein to Avro.
Now that the basic definition is out of the way, let’s get right to it.
How can Parquet help me?
Parquet is exceptionally good at high-speed big data analytics. It can store vast quantities of data and operate on it more quickly than many other solutions. Let’s say you have CSV files in S3 (20 TB and growing by 250GiB per day) and a use case that necessitates reporting on those files in a dashboard. A common approach to this problem is aggregating the CSV files down to a MySQL-friendly size, so that reports can be built on this aggregated data. However, this is limited in multiple ways:
- CSV is slow to parse because it requires reading all of the rows in the entire file, parsing each line’s columns.
- MySQL can only handle so much data, especially high dimensionality data where your users may want to pivot on many different attributes. Every pivot requirement is likely to be impossible to meet, so users must have their functionality restricted for the sake of tech limitations.
- Building many tables to support the various pivot requirements becomes onerous, because each table (and the database itself) has to be limited in both size and scope. This increases database storage costs and complexity.
If those limitations had you cringing, I’ve made my case well :). There is an alternative that utilizes SParquet…
- Process the CSV files into Parquet files (snappy or gzip compressed)
- Use Spark with those Parquet files to drive a powerful and scalable analytics solution
CSV File for Proof of Concept (PoC): NYC TLC Green Taxi for December 2016
The CSV file has 1,224,160 rows and 19 columns, coming in at 107MB uncompressed. Here’s the file schema (using header and inferSchema options in Spark 2.1.1):
|-- VendorID: integer (nullable = true) |-- lpep_pickup_datetime: timestamp (nullable = true) |-- lpep_dropoff_datetime: timestamp (nullable = true) |-- store_and_fwd_flag: string (nullable = true) |-- RatecodeID: integer (nullable = true) |-- PULocationID: integer (nullable = true) |-- DOLocationID: integer (nullable = true) |-- passenger_count: integer (nullable = true) |-- trip_distance: nullable = true) |-- fare_amount: nullable = true) |-- extra: nullable = true) |-- mta_tax: nullable = true) |-- tip_amount: nullable = true) |-- tolls_amount: nullable = true) |-- ehail_fee: string (nullable = true) |-- improvement_surcharge: nullable = true) |-- total_amount: nullable = true) |-- payment_type: integer (nullable = true) |-- trip_type: integer (nullable = true)
Uncompressed CSV of 107MB was reduced to 24MB (Snappy Parquet) and 19MB (GZIP Parquet). But the real power comes in once the data (now in parquet format) is accessed. Parquet is exceptionally fast when accessing specific columns, which is the opposite of row-based file formats, which thrive when accessing an entire row record. Here are simple SQL examples to show the differences:
--#1
--CSV will read the entire file row-by-row
--Parquet will dump the rows based on their column values
--Winner: Parquet (minimal; because of no parsing)
SELECT *
green_tlc
--#2
--CSV will read the entire file row-by-row
--filter the PULocation column to only ones containing 226
--and output all rows/columns that match the filter criteria as the results
--Winner: Parquet (minimal; because of no parsing and push down filtering)
SELECT *
green_tlc
WHERE PULocation = 226
--#3
--Parquet will first find only the relevant "data blocks" based on the filter criteria
--and only aggregate the rows/columns that match the filter criteria
--Winner: Parquet (huge; because of no parsing and only specific columns)
SELECT PULocation, SUM(total_amount)
green_tlc
WHERE PULocation IN (77, 102, 107, 226)
GROUP BY PULocation
#3 above is a great example of where Parquet shines, because you’re using pushdown filtering, operating on only specific columns (the rest are ignored), and do not have to parse what you don’t care about (all the other columns/rows).
What implementation strategies can I use?
Some ideas:
- Spark with Parquet (SParquet) on Livy to be able to cache entire datasets/queries
- Bonus: Impala with Parquet-backed Hive tables (also Spark compatible) to get hyperfast results available via SQL queries
By now, you have hopefully learned that Parquet is a powerful data format that facilitates big data analytics at a scale far greater than many traditional limited approaches. Go forth and play with Parquet!
Here’s my blog post for specific optimization tips: http://garrens.com/blog/2017/04/08/getting-started-and-tips-for-using-apache-parquet-with-apache-spark-2-x/
Garren Staubli is a Big Data Engineer Consultant at Blueprint Consulting Services, and formerly a big data engineer at iSpot.TV.
Very nice evidence-based review!