Switching between Scala and Python on Spark is relatively straightforward, but there are a few differences that can cause some minor frustration. Here are some of the little things I’ve run into and how to adjust for them.
- PySpark Shell does not support code completion (autocomplete) by default.
Why? PySpark uses the basic Python interpreter REPL, so you get the same REPL you’d get by calling python at the command line.
Fix: Use the iPython REPL by specifying the environment variable
PYSPARK_PYTHON=ipython3 before the pyspark command.
Before:
pyspark
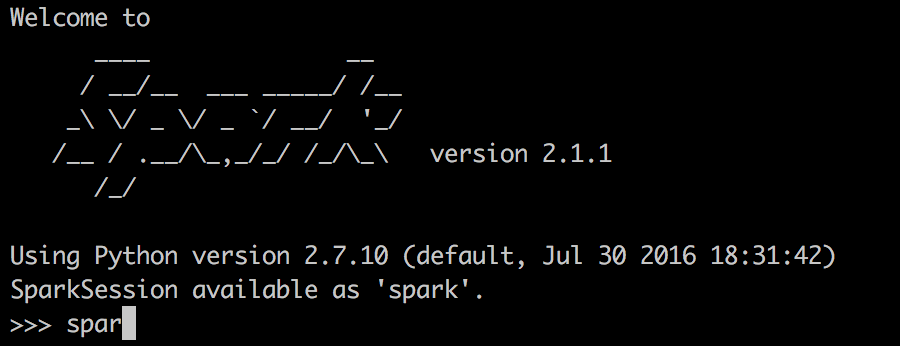
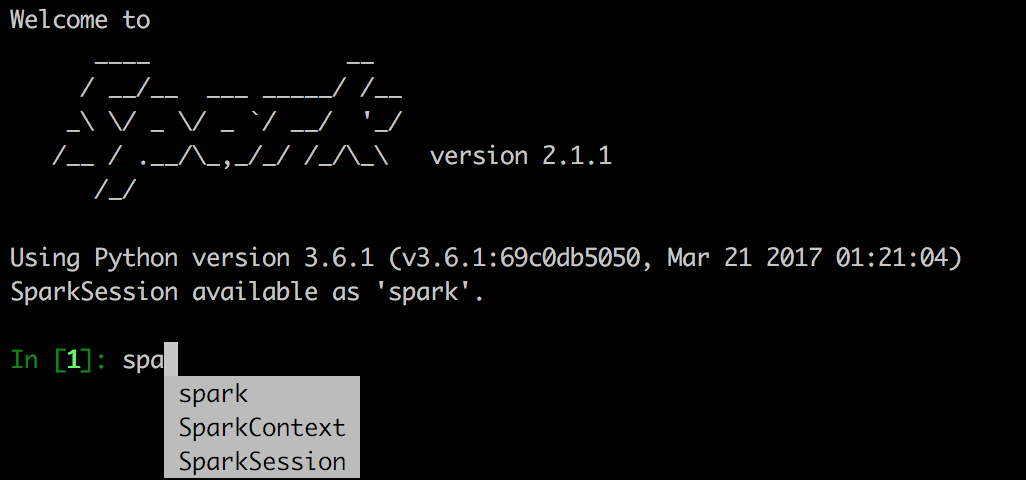
After:
PYSPARK_PYTHON=ipython3 pyspark
- val and var are not python keywords!
This is silly, but I catch myself trying to create variables in python regularly with the val df = spark.read... style.
Before:
>>> val df = spark.range(100)
File "", line 1
val df = spark.range(100)
^
SyntaxError: invalid syntax
After:
>>> df = spark.range(100)
- It’s print not println
Just like the val/var conundrum, println is not a valid keyword in python, but print is!
Before:
In [5]: df.foreach(println)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-5-3d51e5dc3e2b> in <module>()
----> 1 df.foreach(println)
NameError: name ‘println’ is not defined
After:
In [6]: df.foreach(print)
Row(id=3)
Row(id=4)
Row(id=2)
Row(id=1)
Row(id=0)
- All function calls need parentheses in Python
Yep, this is one of those frustrating gifts that just keeps on giving [pain].
Scala:
scala> df.groupBy("element").count.collect.foreach(println)
[bar,1]
[qux,1]
[foo,1]
[baz,1]
Python
Before:
In [15]: df.groupBy("element").count().foreach(print)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
in ()
----> 1 df.groupBy("element").count.collect.foreach(print)
AttributeError: ‘function’ object has no attribute ‘collect’
After:
In [17]: df = spark.createDataFrame([(1,"foo"), (2, "bar"), (3, "baz"), (4, "qux")]).toDF("time", "element")
In [18]: df.groupBy("element").count().foreach(print)
Row(element='bar', count=1)
Row(element='qux', count=1)
Row(element='foo', count=1)
Row(element='baz', count=1)
- Quotes!
Python allows both single (‘) quotes and double (“) quotes for strings. Scala uses the single quote to denote more specific types.
Scala
scala> 'f
res7: Symbol = 'f
scala> 'f'
res6: Char = f
scala> 'foo'
<console>:1: error: unclosed character literal
'foo'
scala> "foo" == 'foo'
"foo" == 'foo'
Python
In [19]: "foo" == 'foo'
Out[19]: True